
Last few months I was involved in a rollout project of a large application on VMware vSphere. During the phases of the rollout, we had few tricky performance issues to solve, but one of them was pretty special. This problem was more than worth writing the article: Scale-Out Application vs. NUMA Action-Affinity
As the title suggests, the application was a typical Scale-Out Application with a lot of workers spread across a single VMware vSphere Cluster.
Note:
All examples and numbers are slightly simplified for better presentation.
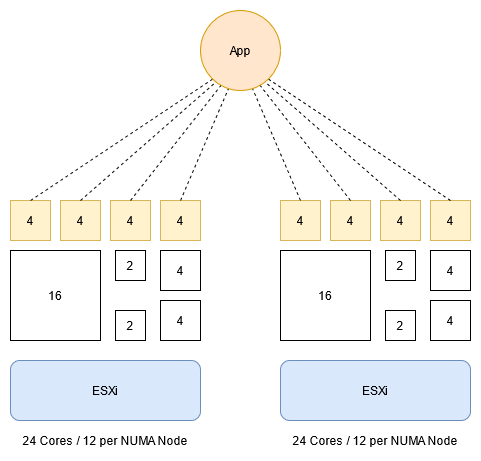
VMware DRS did a great job and distributed all of the worker nodes of the Scale-Out Application across the ESXi hosts of the cluster and placed additional VMs in an efficient way.
But as soon as the load of the Scale-Out Application was increased we identified a huge increase of the CPU Ready (%) counters of the VMs. But not on all VMs, mostly the Scale-Out Application VMs were affected and just a few others. The behavior was pretty atypical from several points of view:
- The over-commitment of the physical CPUs of the ESXi was not pretty high
- Not all VMs were affected and even VMs with more vCPUs had a smaller impact (lower CPU Ready (%))
| vCPUs | Physical Cores | Over-Commitment |
|---|---|---|
| 44 | 24 | 1 : 1,83 |
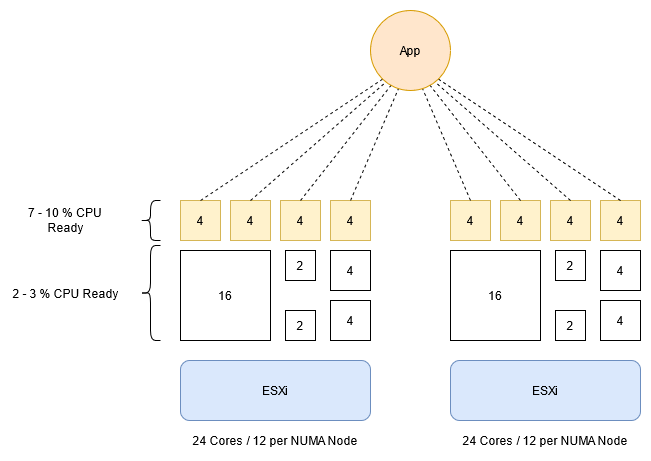
The appearance of NUMA Action-Affinity
As Frank Denneman also wrote about this behavior in his book “VMware vSphere 6.5 Host Resources Deep Dive”, we have been pulling our hair out over this problem. So, what happened here?
The VMware ESXi NUMA scheduler has identified a potential of optimization, based on shared IO context or heavy interaction between the Workers of the Scale-Out Application and did a Locality Migration. This means that all Workers of the Scale-Out Application will be moved to a single NUMA node. The potential benefit of this behavior is a higher cache hit rate for the Scale-Out Application VMs and more available CPU cache resources for the other VMs on the host.
The problem with this situation is that the NUMA scheduler does not take into account the increased CPU over-commitment.
| NUMA | vCPUs | Pysical Cores | Over-Commitment |
|---|---|---|---|
| 0 | 24 | 12 | 1 : 2 |
| 1 | 20 | 12 | 1 : 1,6 |
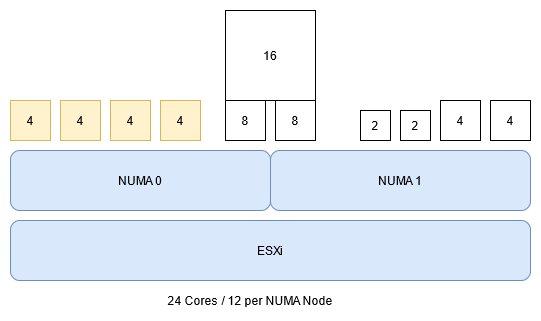
Already with this small example, you see a way higher over-commitment of the NUMA Node 0. This situation compared with a high workload profile (CPU Utilization) of the Scale-Out Application VMs leads to an above-average CPU Ready % of these VMs.
The VMware Knowledgebase Article “NUMA nodes are heavily load imbalanced causing high contention for some virtual machines” describes the problem as follows:
This issue occurs when the CPU scheduler considers the relationship between scheduling contexts and places them closely, NUMA clients might be placed on the same NUMA node due to frequent communication between them. Such relation or action-affinity is not limited between NUMA clients and can also be established with I/O context. This policy may result in a situation where multiple virtual machines are placed on the same NUMA node, while there are very few on other NUMA nodes. While it might seem to be unbalanced and an indication of a problem, it is expected behavior and generally improves performance even if such a concentrated placement causes non-negligible ready time. Note that the algorithm is tuned in a way that high enough CPU contention will break such locality and trigger migration away to a less loaded NUMA node. If the default behavior of this policy is not desirable, this action-affinity-based migration can be turned off by overriding the given advanced host attribute.
This behavior has led me to the article title Scale-Out Application vs. NUMA Action-Affinity because the NUMA Locality Migration breaks the concept of the Scale-Out Application by consolidating them into one NUMA node.
How to Troubleshoot
At first, I need to mention that a higher CPU Ready counter does not necessarily lead to performance degradation if this situation occurs. Some applications can benefit a lot from the higher cache hit ratio and the higher CPU contention is not that important.
But it is always important to identify this situation to be aware off. So, I will highlight some commands you should have a look at:
| Command | Description |
|---|---|
| sched-stats -t numa-pnode | Ressources entitled to the NUMA Nodes. |
| sched-stats -t numa-clients | NUMA counters per VMs (including NUMA Node). |
| sched-stats -t numa-migration | Granular view of the types of migrations per VM. |
| sched-stats -t numa-global | Migration count of the entire system since boot-time. |
The relevant migration counters are called: localityMig (per VM) or localityMigration (Global)
Possible Solutions
DRS in general won’t help to solve this. If the number of Application VMs is smaller or equal to the number of Hosts in the vSphere Cluster, DRS Rules might prevent you from running into that, but typically this isn’t the case (more Application VMs than Hosts).
There are two possible and at the same time realistic solutions for this situation.
Disable Action-Affinity
As this workload has no benefit from additional locality / possible increased cache hit ratio and only negative effects by the increased CPU contention, disabling action-affinity might be a great option.
Set the Advanced System Setting “Numa.LocalityWeightActionAffinity” to “0” and reboot the ESXi Host.
Resize Cluster and Workload
This is definitely the way more complex (and expensive) solution for this problem, but possibly useful in the long term. Because a negative effect on other applications due to the disabled action-affinity is possible.
The solution in one sentence: Add enough hosts to the cluster or scale-up VMs that fewer Workers of the Scale-Out Application are running on a single host and the Locality Migration does not lead to a critical CPU Contention.
Additional Observation
In my case, the use of Side-Channel Aware Scheduler v2 (SCAv2) in combination with older Intel CPU generations (Intel Xeon 61xx) had intensified the negative effects. That behavior makes sense if you have a look at how SCAv2 works, but I have not fully verified this, I had the option to swap the hosts.
Summary
VMware ESXi resource schedulers are designed to meet the vast majority of requirements very well. And even though you may be able to optimize something, it must always be weighed against the risk of making something else worse. The scenario described in this blog post is a corner case and does require additional customization, but that doesn’t mean VMware has done anything wrong here. The VMware Support Team was super fast in confirming the situation and already the knowledgebase had the solution.
Please always note when you change advanced system settings, this is a deviation from the default which means additional work: Tests after major updates, Test when workload significant changes, or even in a troubleshooting scenario you might need to exclude this setting as a possible cause.
Special Thanks
Many thanks to the VMware Team for their great content all around NUMA and ESXi host resources in general, it is not natural to make all these details public. And once again special thanks to Frank Denneman for the great call we had to discuss this situation in detail.
Additional Resources for Scale-Out Application vs. NUMA Action-Affinity
- Book: VMware vSphere 6.5 Host Resources Deep Dive
- VMware Knowledgebase Article “NUMA nodes are heavily load imbalanced causing high contention for some virtual machines”
- Blog Posts: https://frankdenneman.nl/numa/
- NUMA-related VMworld Sessions: 2020. 2019