In this article, I will discuss the various VMware vSphere Site Availability Concepts and will try to work out how each concept can be applied to data centers, sites, and vSphere clusters.
No matter which one of the possible VMware vSphere Site Availability Concepts you choose for your environment, or which mix of them fits your demands, there are some basic rules you should apply to guarantee the best possible availability and minimize the unplanned failovers.
Documentation
Good documentation about the configuration of your infrastructure and the processes you use to operate the different systems are the best foundation for a robust environment.
But your documentation should not only include the current configuration, you should also write down, what needs to be done if something went wrong. This is often called a Failover Plan or Recovery Runbook.
Redundancy
Redundancy is required on all levels of the infrastructure stack to guarantee maximum uptime. And just because you have a second data center, you can’t do without redundancy for the smaller parts, such as cabling or PCI cards. Each unplanned failover (host or the whole site) is stress for your infrastructure.
If you decide to run two datacenters, respective sites, on a single campus the end-to-end redundancy gets very complex. Think about the dedicated power supply and WAN access you need for both datacenters.
But redundancy is not just about equipment, also your IT stuff and their knowledge need to be redundant.
Monitoring
A good Uptime-Monitoring concept that covers all layers of the infrastructure allows you to react quickly to minor outages and probably prevent major incidents. You should consider methods to verify your services from a “User-Perspective”, such as making an API Call instead of a simple HTTP check.
In addition to “simple”, but very important Uptime-Monitoring, an IT Operations Management Tool can help you to efficiently operate complex infrastructures and proactively react to changes and trends.
Maintenance
Keeping your systems up to date is not just about security, this is also about proactively preventing failures caused by software and firmware defects.
In my opinion, there is another important thing in doing maintenance of your systems: You learn more about the systems.
Testing
A Failover-Plan or a Backup is nothing worth without regular testing and verification. Each change of the environment needs to be verified against your existing failover and restore processes.
Tools like VMware Site Recovery Manager or Veeam Availability Orchestrator are able to verify failover scenarios in a non-disruptive way. Veeam Availability Orchestrator even generates documentation for the failover plan.
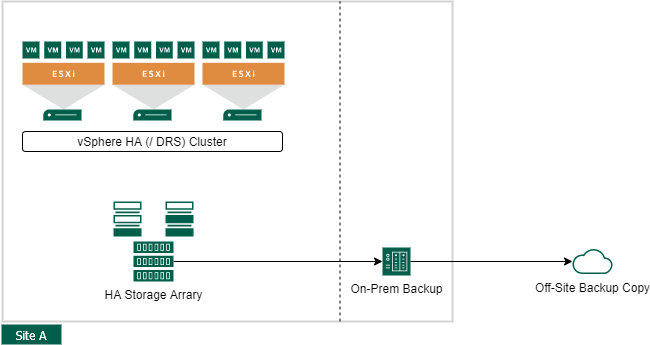
Single Datacenter
I will start with the cheapest and simplest of the VMware vSphere Site Availability Concepts, a single data center that contains the whole production site. However, the fact that the production data is all in one location does not mean that the backup data could not be replicated off-site. On the contrary, in this constellation this is even an urgent recommendation. Some backup vendors offer a tight integration for off-site backup locations - Veeam, for example, has a huge ecosystem of Veeam Cloud Connect Providers.
| Metric | Rating |
|---|---|
| Complexity | Low |
| Cost | Low |
| RPO Time * | High |
| RTO Time * | High |
| Possible Distance | N/A |
* Full Site Failure
This design is probably the most common setup for SMB customers and remote branches. A good data center monitoring and backup concept might reduce the general chance of a site failure and reduces the RPO / RTO time in case of a storage failure. The backup concept should also include, if possible, a dedicated location (another fire compartment) for the backup data. If the data center is a remote branch, your backup can be copied to the main datacenter.
Keep in mind that an off-site copy of your backup data is nothing worth without a recovery concept and routinely testing.
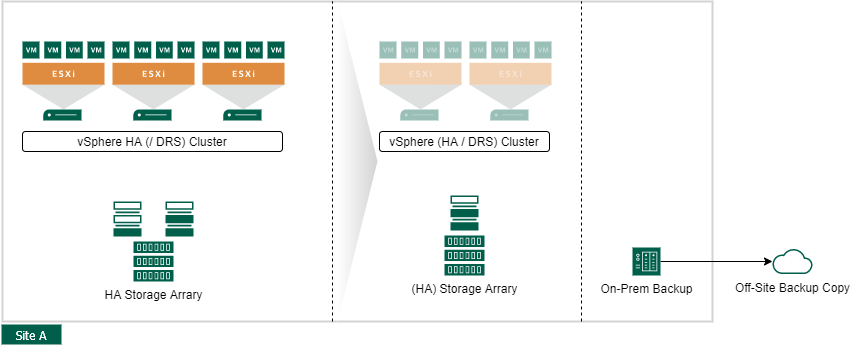
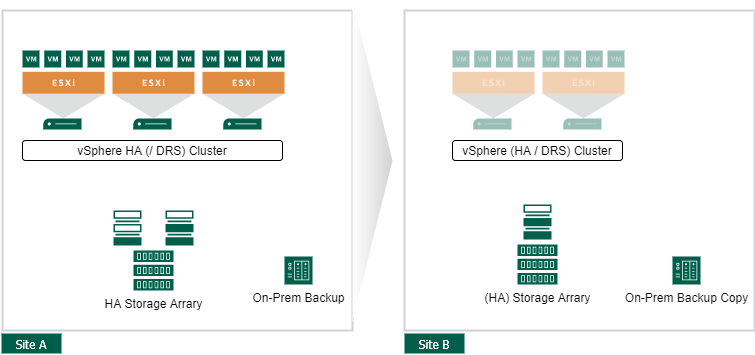
Active Passive Datacenter
An active-passive data center is the next evolution of a single datacenter. It can also be designed very cost-efficient and deployed in various scenarios.
- Two data centers in one site
- A Second data center off-site but on-premises
- A second data center in the cloud
All of the deployment scenarios are based on the replication of the VMs. Storage Array replication can be a way to increase the efficiency of the replication, by offloading this task to another layer than the hypervisor. But typically this type of offloading reduces the flexibility in the choice of the second location. On top of the replication itself, should be added an orchestration solution for the failover. Two well-known products for that use case are:
An active-passive data center concept can be set up with one ore two VMware vCenter Server instances. A single vCenter Server setup comes with some limitations and more complex failover scenarios.
The possible distance between the sites or data centers is depending on the replication method. Most of the asynchronous replication technologies allow very long distances, respective round trip times between the sites.
| Metric | Rating |
|---|---|
| Complexity | Medium |
| Cost | Medium |
| RPO Time * | Medium |
| RTO Time * | Medium |
| Possible Distance | Long |
* Full Site Failure
In most cases, the secondary data center (passive data center) is way lower equipped and not able to run the full workload of the first site. But you are able to start pretty fast the most critical workloads in a scheduled and validated way. Some concepts include, that infrastructure services like NTP, DNS, and Active Directory are actively running on the secondary site to speed up the failover.
In the case of a full data center or site loss, the planned and validated failover gives you the time to add more hardware to the secondary datacenter and bring up the additional services (in the worst case from the backup).
One of the critical parts of this concept is once again the disaster recovery plan. To add full value to the secondary data center you need to think about the connectivity to the services you re-launch there. Perhaps you need a concept for accessing these services via a VPN gateway or a small terminal server farm.
If your availability concept includes a secondary site in the cloud, you are able to use the same tools as on-premises. VMware Site Recovery Manager, for example, is able to leverage VMware Cloud on AWS for on-demand Disaster Recovery as-a-Service and Veeam offers Disaster Recovery-as-a-Service (DRaaS) through their Veeam Cloud Connect Providers.
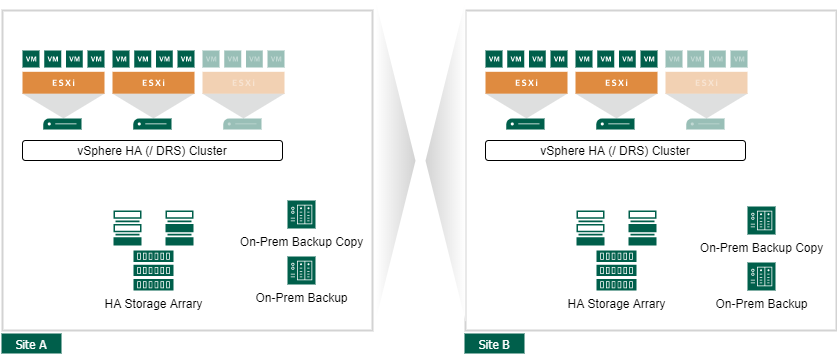
Active Active Datacenter
The same deployment scenarios are possible for active-active data center setups as for active-passive setups. The main difference is that there is no primary and secondary location, both sites have active workloads and the additional compute headroom for the workload of the other site. The VMs are cross-site synchronously ar asynchronously replicated.
As you need the same equipment on both sites, this concept is more expensive than the active-passive setup. The advantage is that VMs are recovered in an actively used data center, so there is less risk of complications and fewer steps to the failover plan.
An active-active datacenter setup only makes sense with two vCenter Server instances, one per site. This also eliminates possible problems with the high round-trip times (RTT) between vCenter Server and ESXi Hosts (maximum is 10ms RTT).
| Metric | Rating |
|---|---|
| Complexity | Medium |
| Cost | Medium |
| RPO Time * | Medium |
| RTO Time * | Low |
| Possible Distance | Long |
* Full Site Failure
VMware vSphere Metro Storage Cluster
An availability concept based on a Metro Storage Cluster is from an availability perspective at the top of the line of the possible VMware vSphere Site Availability Concepts. All data is mirrored to the second data center and a site-failover is handled completely transparent. From a vSphere perspective, a site failure is handled like a “simple” vSphere HA event.
VMware vSphere® Metro Storage Cluster (vMSC) is a specific storage configuration which is commonly referred to as stretched storage clusters or metro storage clusters. These configurations are usually implemented in environments where disaster and downtime avoidance is a key requirement.
VMware vSphere® Metro Storage Cluster Recommended Practices > Purpose and Overview
There is a long list of technical requirements and constraints on VMware vSphere and storage level. If you are interested in this concept you should carefully read the VMware vSphere® Metro Storage Cluster Recommended Practices and the documentation from your preferred storage vendor.
Some of the requirements of this concept also differ between the storage vendors. Most of the storage arrays that support metro cluster setups require a site-local placement of the vSphere VMs to guarantee the best performance and support for all possible failure scenarios. The Dell EMC PowerMAX family SRDF/Metro, for example, does not have this requirement, both sites actively read and write to all LUNs.
The problem of site-local placement of the VMs can easily be solved by using a dedicated Storage DRS Cluster for the datastores of each site and DRS Groups / Rules for Host to VM Soft-Affinity.
One big advantage of this concept is also a disadvantage in some cases: All data is replicated. This is an advantage for applications that do not have a native availability concept, but an application that replicates the data itself consumes a lot of additional storage space without any further benefit.
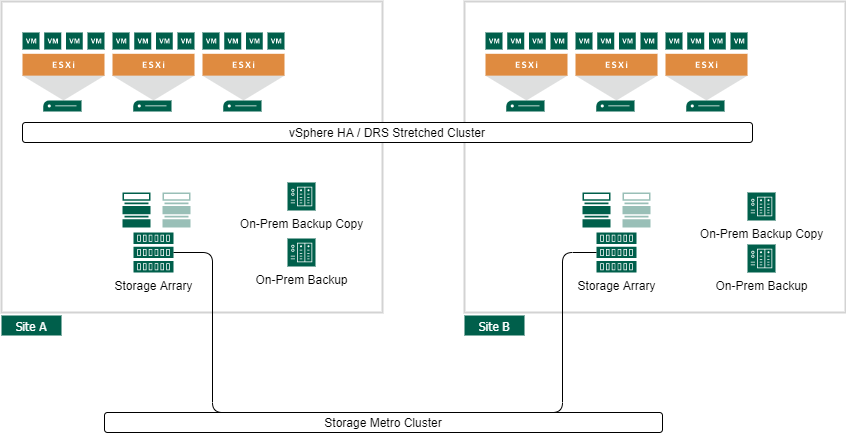
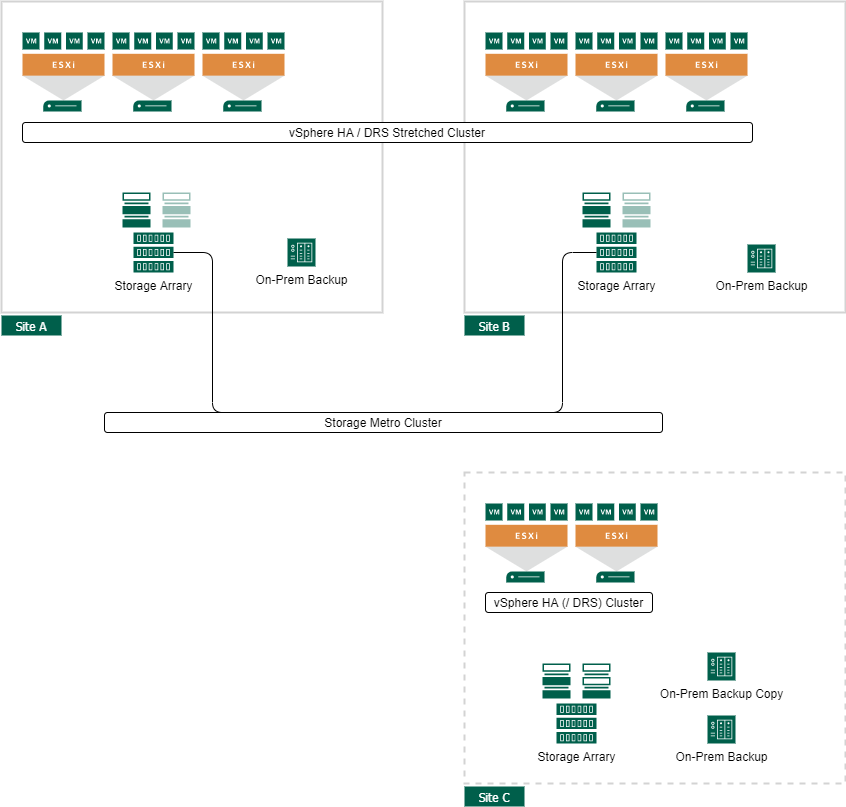
In most large enterprise or service provider environments, I have seen the need for a third location to run Quorum or Tie-Breaker systems for some applications or the storage cluster itself. If this dedicated site is available, it can also be used for backup or additional storage replication. Take a look at the Veeam NetApp Data ONTAP integration with Backup from secondary snapshots if you are interested in offloading the whole backup process to a dedicated location.
| Metric | Rating |
|---|---|
| Complexity | High |
| Cost | High |
| RPO Time * | Low |
| RTO Time * | Low |
| Possible Distance | Medium |
* Full Site Failure
The possible distance between the sites or data centers is limited by the vMotion Round-Trip Time (150 ms for Long-Distance vMotion Migration) and the storage requirements for the mirror. The most commonly supported maximum RTT for storage systems is 5ms. Please keep also in mind that you add the latency between the sites as storage latency on top.
The transparent storage failover mechanism does not relieve the need for regular emergency testing and setup validation at all levels of the infrastructure.
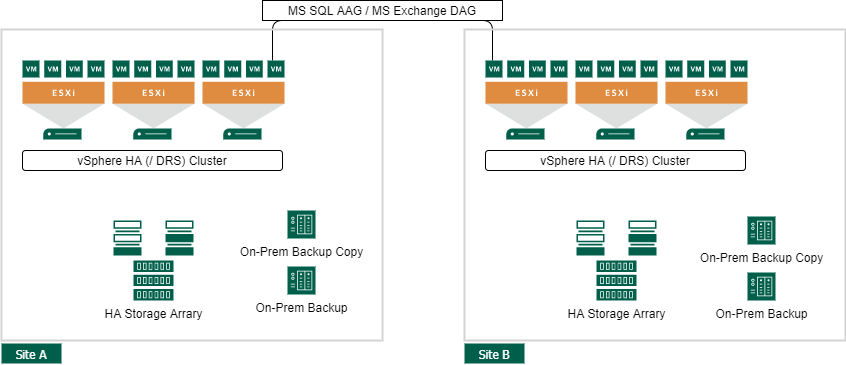
Site Availability on Application level
This a special concept, perfectly fitting for applications that create their own data and service availability on the application level. Common applications of this concept are Microsoft SQL AAG, Microsoft Exchange DAG, or SAP HANA with System Replication. Also conceivable would be services that do not have persistent data and can be distributed by a Load Balancer across sites, such as a web server cluster or a terminal server farm. But keep in mind that such systems usually require additional app tiers with persistent data, such as a database server or a file server.
Some of the advantages over a VMware vSphere Metro Storage Cluster are:
- No additional storage latency caused by the mirror
- More independence possible on all infrastructure layers
- No additional data duplication by the storage mirror
But the big downside is, you need the failover and redundancy capability on the application level.
| Metric | Rating |
|---|---|
| Complexity | Medium |
| Cost | Medium |
| RPO Time * | Low |
| RTO Time * | Low |
| Possible Distance | Medium |
* Full Site Failure
Summary
It’s important to know, that there is not the “best” of the possible VMware vSphere Site Availability Concepts. The chosen setup must fit your requirements and possibilities. Here is a list of some of the main factors that influence the requirements and possibilities:
- IT Budged
- Applications to run (and their availability concept)
- IT Stuff
- Business demands
- Workplace concept
Some examples:
If your companies reputation is at risk in case of some unavailable services, you need to invest in a robust and highly available environment.
If your IT Stuff is a “One-Man-Show” for the whole infrastructure stack, you are not able to fully operate a VMware vSphere Metro Storage Cluster environment.
If all your employers use SaaS solutions (Office 365, Salesforce) for their daily business, you probably do not have any availability requirement for your local datacenter.
If your company loses money in case of some unavailable services, you need to invest in a robust and highly available environment.
In most of the large enterprise or service provider environments, I have seen a mix between Site Availability on Application level and VMware vSphere Metro Storage Cluster. This means one or more VMware vSphere Stretched Clusters and one or more Site-Local HA-Clusters in a single vCenter Server instance. A dedicated vCenter Server instance and a management-level vSphere cluster are also common.
I would very much appreciate your opinion of my line-up and rating of the possible VMware vSphere Site Availability Concepts.